 Single Grain AI Team
Single Grain AI Team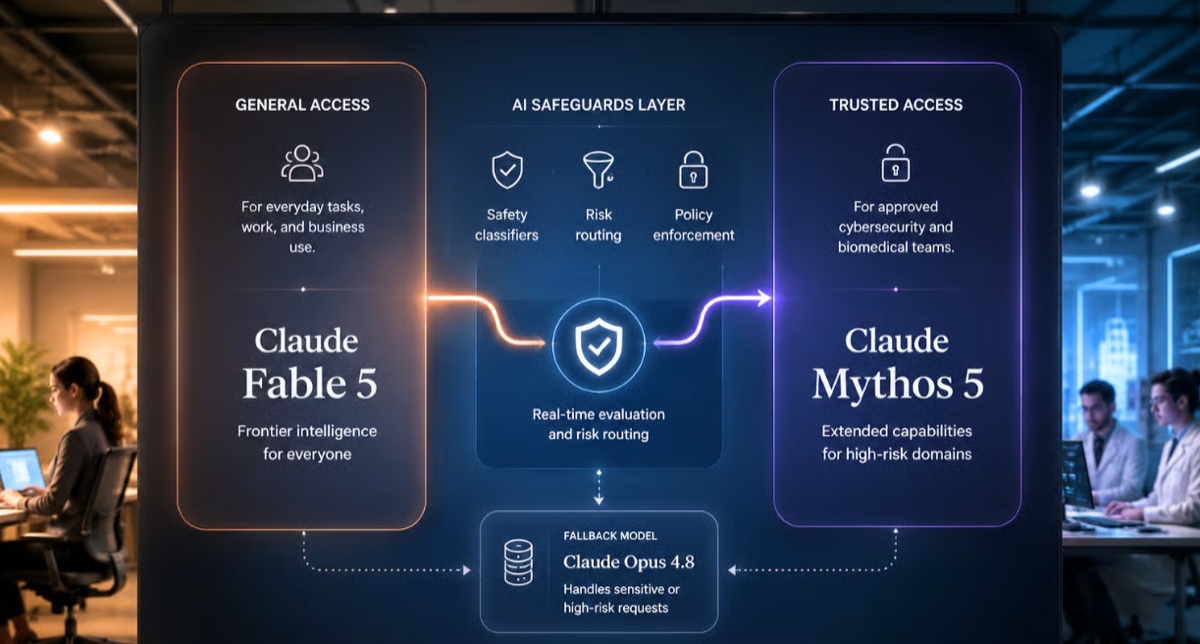
The serious teams are not asking whether AI can act. They are asking when it should stop.
Key takeaways
- Define the owner, authority, evidence standard, and fallback before scaling measurement work.
- Measure adoption, output quality, exception volume, user trust, cost, and risk separately.
- Treat AI systems as living operating systems that need review, monitoring, and maintenance.
- Make boundaries easy to explain so executives, users, and risk teams can challenge the system intelligently.
Why this matters now
The hidden maintenance cost of AI systems sits directly inside one of the most important shifts in applied AI: retrieval quality becoming a business-owned operating discipline. The early wave of AI adoption rewarded teams that could move quickly, experiment publicly, and show visible prototypes. The next wave rewards teams that can make AI dependable inside ordinary business work. That is a much higher bar. It requires better judgment, cleaner ownership, and a practical way to know whether the system is still helping after the launch excitement fades.
For finance leaders, operating executives, analytics teams, and AI program managers, the issue is no longer whether models can produce plausible output. They can. The sharper question is whether measurement can absorb that output without creating confusion, unmanaged risk, or hidden operational cost. Aster Lane AI keeps returning to this theme because it is where AI strategy becomes real: not in the announcement, not in the vendor demo, but in the recurring decisions that determine how work is approved, reviewed, escalated, and improved.
The latest market conversation around AI security teams testing prompt injection, tool permissions, and data leakage before launch has made this especially urgent. Teams now have access to more capable models, richer context windows, better orchestration tools, and more polished interfaces. Capability has risen faster than management practice. That gap is where disappointing AI programs happen. A system may be technically impressive and still fail because no one defined the owner, the exception path, the measurement baseline, or the conditions under which the workflow should pause.
The decision behind the headline
The practical decision behind the hidden maintenance cost of ai systems is not a slogan. It is a question of operating design: whether the program is creating durable value after the novelty period ends. Leaders should treat that question as a working artifact. It belongs in the intake brief, the product review, the vendor comparison, and the post-launch review. If the team cannot answer it simply, the project is probably not ready for more scale.
A useful way to frame the decision is to separate three layers. The first layer is user value: what task, decision, or handoff becomes meaningfully better? The second layer is control: who can approve, correct, pause, or override the system? The third layer is evidence: what observations will prove that the workflow is working under real conditions? Most weak AI programs skip directly to tooling and then try to reconstruct these layers after the system is already in motion.
This is why serious teams write down their assumptions. They name the expected behavior, the known failure modes, the quality standard, and the cost boundary. They also name the people who will notice when those assumptions stop being true. That small discipline changes the emotional temperature of AI work. Instead of arguing about whether the technology is impressive, teams can discuss whether the system is earning trust in the workflow where it operates.
What strong teams do differently
Strong teams make measurement visible. They build dashboards, review queues, approval steps, and audit trails that match the authority of the AI system. A low-risk drafting assistant may need light review and basic usage monitoring. A workflow that touches customer communication, pricing, eligibility, data access, security operations, or executive reporting needs stronger evidence and a clearer human decision path. Treating both systems the same is how governance becomes either too heavy or too weak.
They also avoid the common trap of measuring only speed. Speed matters, but it is not the whole business case. The right measurement set includes adoption, output quality, exception volume, review time, support burden, user confidence, infrastructure cost, and risk events. If AI makes one step faster while pushing more work into cleanup, escalation, or customer support, the program has not created the value the demo suggested.
The strongest teams turn feedback into maintenance. They do not treat user complaints, bad generations, missing context, or confused handoffs as anecdotes. They treat them as operating signal. Those signals feed prompt updates, retrieval cleanup, policy changes, product design fixes, and training. AI systems are not static assets. They are living operational systems that need stewardship.
A practical operating model
A practical model begins with intake. Every proposed AI use case should state the user, the business owner, the technical owner, the data involved, the intended action, the risk class, and the fallback plan. This does not need to become a slow committee process. It can be a two-page working brief. The point is to prevent the team from discovering basic accountability questions after a model has already been connected to production work.
Next comes evaluation. The evaluation set should be built from realistic examples, not just generic prompts. It should include easy cases, edge cases, failure cases, adversarial cases, and examples where the system should refuse, ask for more information, or route to a human. A good evaluation set becomes a shared language between product, engineering, risk, and operations. It lets teams discuss behavior instead of impressions.
Finally, the launch plan should include an operating cadence. During the first weeks, teams should review usage, quality, exceptions, cost, and user feedback frequently. After stabilization, the cadence can slow, but it should not disappear. The moment no one is reviewing the system is the moment drift becomes invisible. For AI systems with meaningful authority, invisibility is not efficiency. It is unmanaged exposure.
The common failure pattern
The most common failure pattern is overconfidence after a successful pilot. A small group tests the system, the outputs look impressive, and leadership approves expansion before the messy realities of scale are understood. More users bring more varied inputs. More data sources introduce more contradictions. More integrations create more permission questions. More automation creates more need for replayable logs. The pilot did not lie; it was simply too small to reveal the operating surface.
Another failure pattern is vague ownership. Everyone agrees the AI system is important, but no one owns the recurring burden of quality review, policy updates, vendor monitoring, user education, or exception handling. In that environment, problems become political. The business blames the model. The technical team blames requirements. Risk teams arrive late. Users create workarounds. The solution is not more enthusiasm. It is a clearer operating contract.
A third failure pattern is treating AI as a feature rather than a work system. Features can ship and move on. Work systems need maintenance, observability, training, and controls. When a model influences decisions, communications, or operational actions, it becomes part of the company's management system. That is why the hidden maintenance cost of ai systems deserves more serious attention than a typical software enhancement.
How to brief executives
Executives do not need every technical detail. They need a decision-ready view. A strong executive brief explains what the system does, where it is used, what authority it has, what evidence supports it, what risks remain, what controls exist, and what the next investment will change. The brief should be short enough to read and specific enough to challenge. If the executive summary relies on words like transformation, acceleration, or intelligence without measurable nouns, it is not ready.
A useful briefing phrase is: "This system is allowed to do X, using Y context, for Z users, under these review conditions." That sentence forces clarity. It reveals whether the project has a real boundary. It also helps executives compare AI investments across departments. Without a shared format, every team describes its work differently, and leadership cannot tell which programs are mature, risky, duplicative, or underfunded.
The board-level version should add accountability and risk appetite. Directors should ask what the system may not do, who can stop it, what would trigger escalation, and how management knows the program is still delivering value. This is not anti-innovation. It is the discipline that allows innovation to scale without becoming operational theater.
Questions worth asking this week
Who owns the business outcome connected to the hidden maintenance cost of ai systems, and do they have enough authority to change the workflow?
What evidence would convince a skeptical operator that the system is improving quality, not just producing more output?
Where could the system create hidden work for review teams, support teams, security teams, or customers?
What data, context, or permission should the system not have, even if access would make the demo look better?
If the system behaves badly for a week, who would notice first, and what would they do?
Implementation checklist
Start with a decision register. The register should list the AI system, the owner, the user group, the workflow boundary, the model or vendor dependency, the data sources, and the current release status. This sounds administrative, but it becomes extremely useful when the company has more than three AI initiatives. It lets leaders see overlap, risk concentration, and maintenance burden before those problems become expensive.
Create a quality review set that belongs to the business, not only to engineering. The set should include realistic examples, disputed examples, edge cases, and examples where the correct behavior is to slow down. For measurement, the most valuable evaluation cases often come from support tickets, rejected drafts, manual exceptions, compliance questions, and messy customer situations. These examples keep the system grounded in the real work rather than idealized prompts.
Give the workflow an operating dashboard. The dashboard does not need to be elaborate at first. It should show usage, completion rate, exception volume, user edits, escalation reasons, cost, latency, and the top recurring failure modes. The point is to create a shared picture of reality. Without a dashboard, teams rely on anecdotes. With a dashboard, they can prioritize the next improvement with more discipline.
Schedule a post-launch review before the launch happens. Put it on the calendar for two weeks after release and again after the first full business cycle. The review should ask what improved, what broke, what users ignored, what reviewers corrected, what costs changed, and what should be stopped. This is where AI programs become better than software rollouts that simply ship and disappear. The review makes learning part of the system.
Finally, keep the language human. Users and executives should not need a glossary to understand the system's purpose. A good description says what the AI does, what it uses, what it cannot do, and who is responsible for decisions. Clear language is not cosmetic. It is a control. The clearer the system is, the easier it is to govern, support, and improve.
One more practical move is to publish a short internal release note for every meaningful change. The note should explain what changed, why it changed, which users are affected, which metrics should move, and which risks need attention. This creates institutional memory. Six months later, when a model, prompt, workflow, or policy needs review, the team can see the chain of decisions instead of reconstructing it from Slack messages and memory.
The Aster Lane view
The hidden maintenance cost of AI systems is not a narrow technical topic. It is a test of whether the organization can turn AI capability into durable operating advantage. The companies that do this well will not necessarily be the ones with the flashiest demos. They will be the ones with clear owners, grounded measures, honest risk conversations, and product experiences that let users understand what the system is doing.
The phrase we keep coming back to is simple: "make the system earn its authority." If AI drafts, recommends, routes, decides, summarizes, searches, monitors, or acts, it should earn that role through evidence. It should be observed in production. It should be correctable by users. It should have boundaries that are easy to explain. It should make the work better enough that the organization would miss it if it disappeared.
That is the serious work ahead. AI is becoming more capable, more embedded, and more autonomous. The response should not be fear, hype, or passive adoption. The response should be better operating design. Teams that build that discipline now will have an advantage that does not depend on a single model release. They will know how to absorb new capability without losing control of the work.
FAQ
Why does the hidden maintenance cost of ai systems matter in 2026?
It matters because AI systems are moving from isolated pilots into production workflows with real authority. Teams need operating discipline, evidence, and clear ownership to make that shift safely.
What should leaders measure first?
Start with adoption, quality, exception volume, review burden, cost per useful action, and user trust. Speed alone is not enough to prove business value.
Who should own this work?
A business owner should own the outcome, while technical and risk owners support implementation, monitoring, and review. Measurement work fails when ownership is vague.

 Eric Kim
Eric Kim
 David Vance
David Vance